
Claude Opus 4.8が発表
Anthropicは2026年5月28日、Claude Opus 4.8を発表しました。公式発表では、Claude Opus 4.7を土台に、コーディング、エージェント的な作業、推論、実務的な知識作業などで改善した新バージョンとして説明されています。
今回の発表で重要なのは、単に新モデルが出たという点だけではありません。Claude Codeの大規模作業向け機能、claude.ai側のeffort control、APIでのモデル名、fast modeの価格変更まで含めて、Claudeを「長い作業を任せる道具」として強化する方向がはっきり出ています。
公式発表:
Introducing Claude Opus 4.8
Opus 4.7からの主な改善点
AnthropicはClaude Opus 4.8について、Opus 4.7からベンチマーク全般で改善し、より効果的な協働相手になったと説明しています。特に、エージェント的なタスクでの判断力、ツール利用、長い作業の進め方が改善点として前面に出されています。
公式発表では、早期テスターのコメントとして、Claude Codeで計画の妥当性を確認したり、自分のミスを検出したり、複雑な調査の前に十分な確信を積み上げたりする点が評価されています。これは、単純な出力品質だけでなく、実務の途中でどれだけ危ない進め方を避けられるかを重視した改善と読めます。
正直さ「honesty」が4倍向上
もう一つ目立つのは「honesty」に関する説明です。Anthropicは、Opus 4.8が根拠の薄い進捗を自信ありげに主張しにくくなり、作業上の不確実性をより明示しやすくなったとしています。自分が書いたコードの欠陥を見逃す確率が Opus 4.7 の約1/4に低下したと説明しています。コードやエージェント作業では、できていないことをできたように見せない性質が重要なので、この点は実務利用では見逃せません。

外部ベンチマークでも高い評価
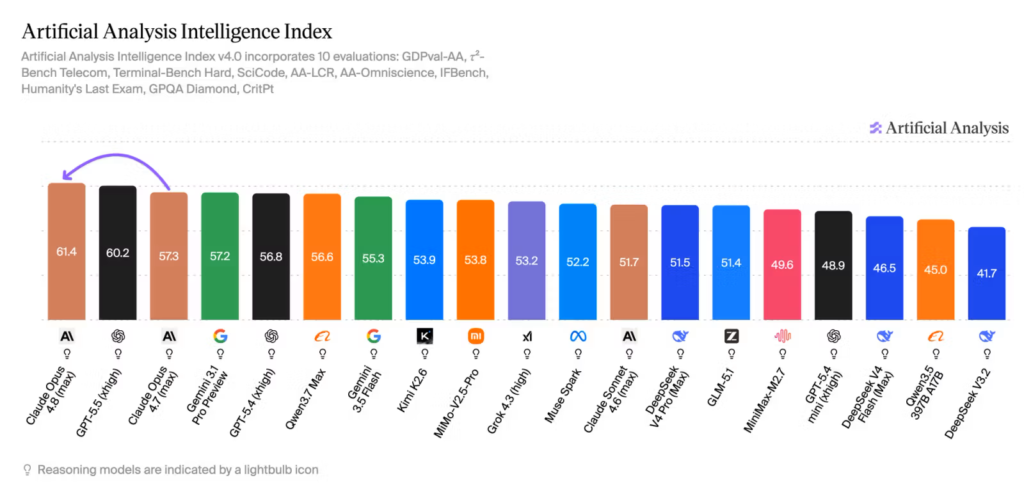
外部評価としては、Artificial AnalysisもClaude Opus 4.8を高く評価しています。同社の記事では、Claude Opus 4.8がArtificial Analysis Intelligence Indexで61.4を記録し、Opus 4.7から+4.1ポイント伸びたとされています。
また、Artificial Analysisは、Claude Opus 4.8が前回のIndex首位だったGPT-5.5 xhighを+1.2ポイント上回ったとも説明しています。エージェント的な実務タスクや科学的推論などで改善が見られるという評価で、公式発表が強調する「より信頼できる協働相手」という方向性とも重なります。
ただし、外部ベンチマークは評価条件、タスク構成、重み付けによって見え方が変わります。そのため、これは公式発表とは分けて、あくまで外部評価のひとつとして見るのがよさそうです。
参照:
Claude Opus 4.8 takes the lead on the Artificial Analysis Intelligence Index
Claude Codeのdynamic workflows
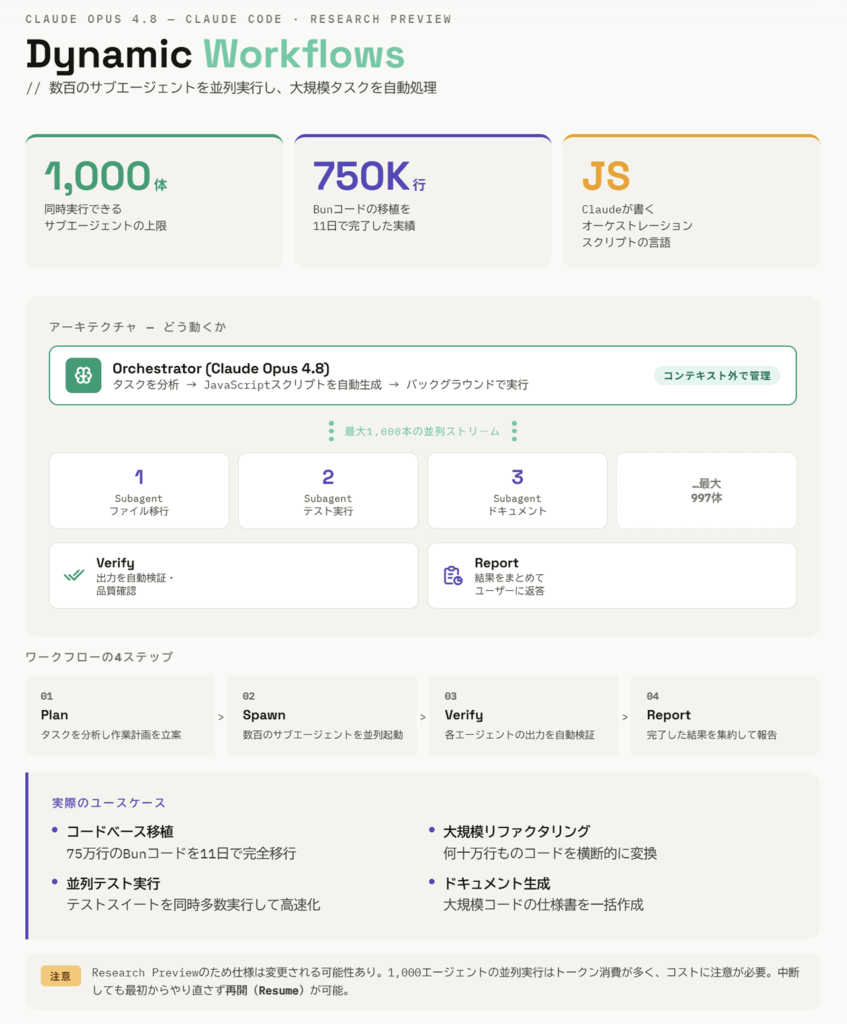
Claude Codeでは、dynamic workflowsという新機能がresearch previewとして追加されました。これは、Claudeが大きな作業を計画し、単一セッション内で多数の並列サブエージェントを走らせ、出力を検証してから報告するための機能です。
Anthropicは例として、Claude Code with Opus 4.8が、数十万行規模のコードベース移行を開始からマージまで進め、既存のテストスイートを品質基準として使うようなケースを挙げています。これは、AIコーディング支援が「1ファイルの修正」から「大きな変更作業の運用」に近づいていることを示す更新です。
ただし、この方向は便利さと同時に運用上の確認ポイントも増やします。並列サブエージェントが増えるほど、権限、差分レビュー、テスト、失敗時の切り戻しをどう設計するかが重要になります。
effort controlとfast modeの意味
claude.aiとCoworkには、Claudeがタスクにどれだけ労力をかけるかを選べるeffort controlが追加されました。高いeffortではより深く考え、低いeffortでは速く応答し、利用上限を抑えやすくなるという位置づけです。
Anthropicは、Opus 4.8のデフォルトをhigh effortにしていると説明しています。コーディングタスクではOpus 4.7のデフォルトと近いトークン量で、より良い性能を狙う設計だとされています。一方で、extraやmaxを選ぶと、より多くのトークンを使って難しいタスクや長時間の非同期ワークフローに対応する方向になります。
- Low — 高速・最軽量。大量処理パイプラインや単純タスク向け
- Medium — 日常の軽いタスク。速度と深さのバランス重視
- High(デフォルト) — 全サーフェスのデフォルト設定。知識集約タスクに最適
- xhigh — コーディング・エージェント作業に推奨
- Max — 最大思考バジェット。xhigh + Dynamic Workflows = Ultracodeとして超大規模タスクに対応
fast modeについても変更があります。Opus 4.8のfast modeは、2.5倍の速度で動作するモードとして説明され、従来モデル向けのfast modeより3分の1の価格になったとされています。通常利用の価格はOpus 4.7と同じで、APIではclaude-opus-4-8というモデル名で利用できます。
Redditで見える初期の反応
Redditでは、r/ClaudeAIで「Introducing Claude Opus 4.8」と「Let’s check Opus 4.8 – How good is it?」が目立っていました。発表そのものへの関心は高く、性能改善やClaude Codeまわりの更新を試したいという空気があります。
一方で、反応は単純な歓迎だけではありません。観測した範囲では、利用量、制限、課金、品質の安定性に関する不安も並んでいました。特に、effortを上げるほど出力品質が上がる設計は、便利である一方、利用量やコストの見通しをどう立てるかという論点を生みます。
r/AgentsOfAIでは、「Every Opus 4.8 default is tuned to make you spend more」という趣旨のスレッドも見られました。これは事実断定というより、エージェント利用が高機能化するほど、トークン消費やプラン選択への警戒も強まることを示す初期の反応として扱うのがよさそうです。
関連スレッド:
- Introducing Claude Opus 4.8
- Let’s check Opus 4.8 – How good is it?
- Anthropic is about to become the first profitable AI company. Every Opus 4.8 default is tuned to make you spend more.
開発者向けにはどう見るべきか
開発者やチーム利用の観点では、Claude Opus 4.8は「より賢いモデル」というより、「長い作業を任せるための設計が進んだモデル」と見るのが自然です。dynamic workflows、effort control、Messages APIの更新はいずれも、単発のチャットではなく、継続的な作業やエージェント運用を意識したものです。
同時に、初期反応が示しているように、高機能化はそのまま安心につながるわけではありません。作業を任せる範囲が広がるほど、レビュー、ログ、権限、予算上限、失敗時の停止条件を明確にする必要があります。
Claude Opus 4.8は、性能改善への期待と、利用量・コスト管理への警戒が同時に出やすいアップデートです。今後は、実際のClaude Code利用やAPI運用の中で、どのeffort設定がどの作業に向いているのか、fast modeがどの程度実務で使いやすいのかが焦点になりそうです。

